Fewer no-shows with automated reminders across Carepatron practices.
Star rating across 900+ reviews on Capterra and G2.
Hours saved per week on average by removing manual scheduling from your workflow.
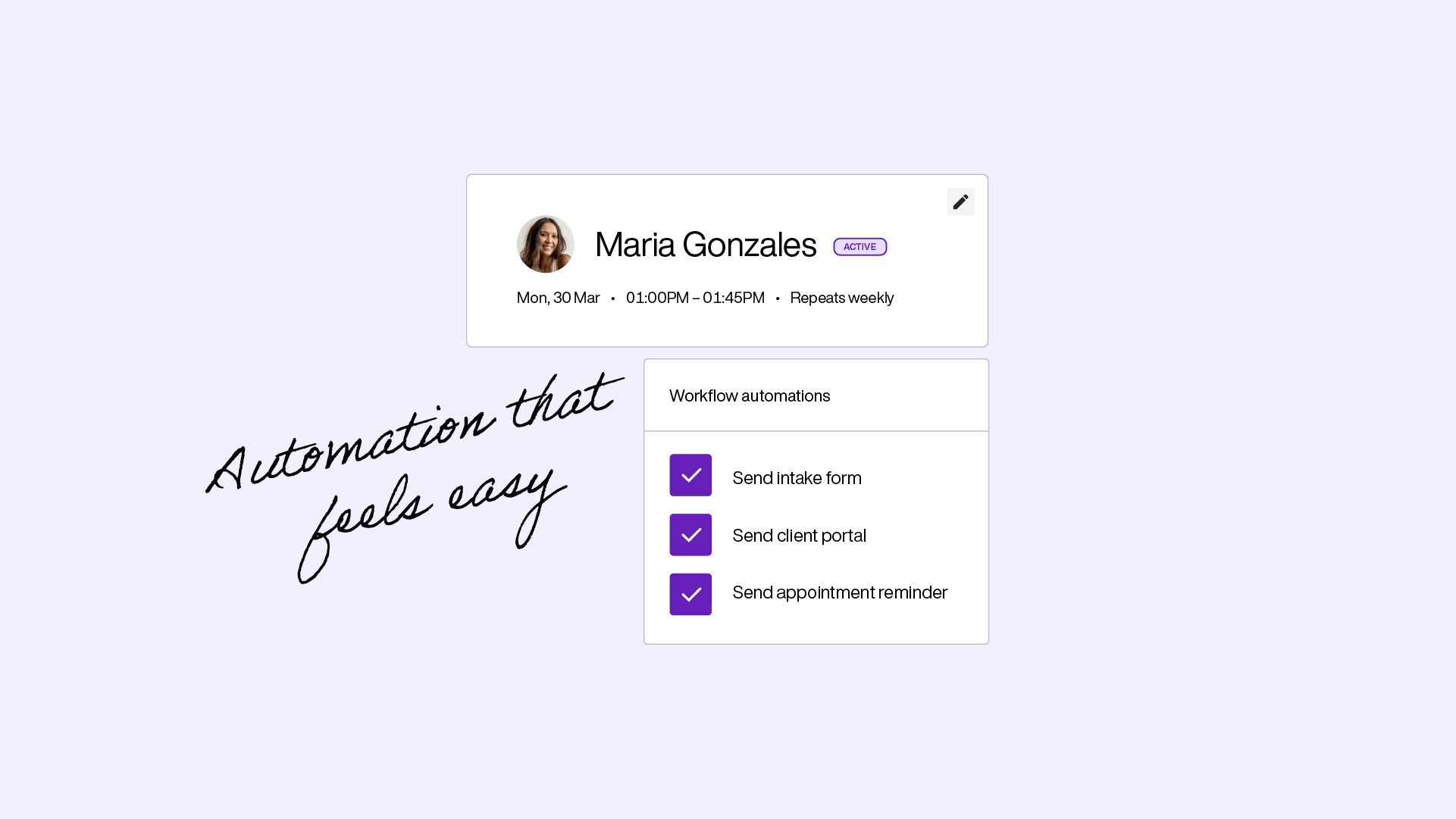
Admin on autopilot
Work just happens
You finish a session, the note is already drafted, an invoice is ready and tomorrow's client has been sent their intake forms. You didn't do any of it – the gaps between clients are yours again.
- Notes drafted during sessions, ready for your review
- Intake forms, reminders, and follow-ups triggered automatically
- Invoices and payment nudges sent without you thinking about it
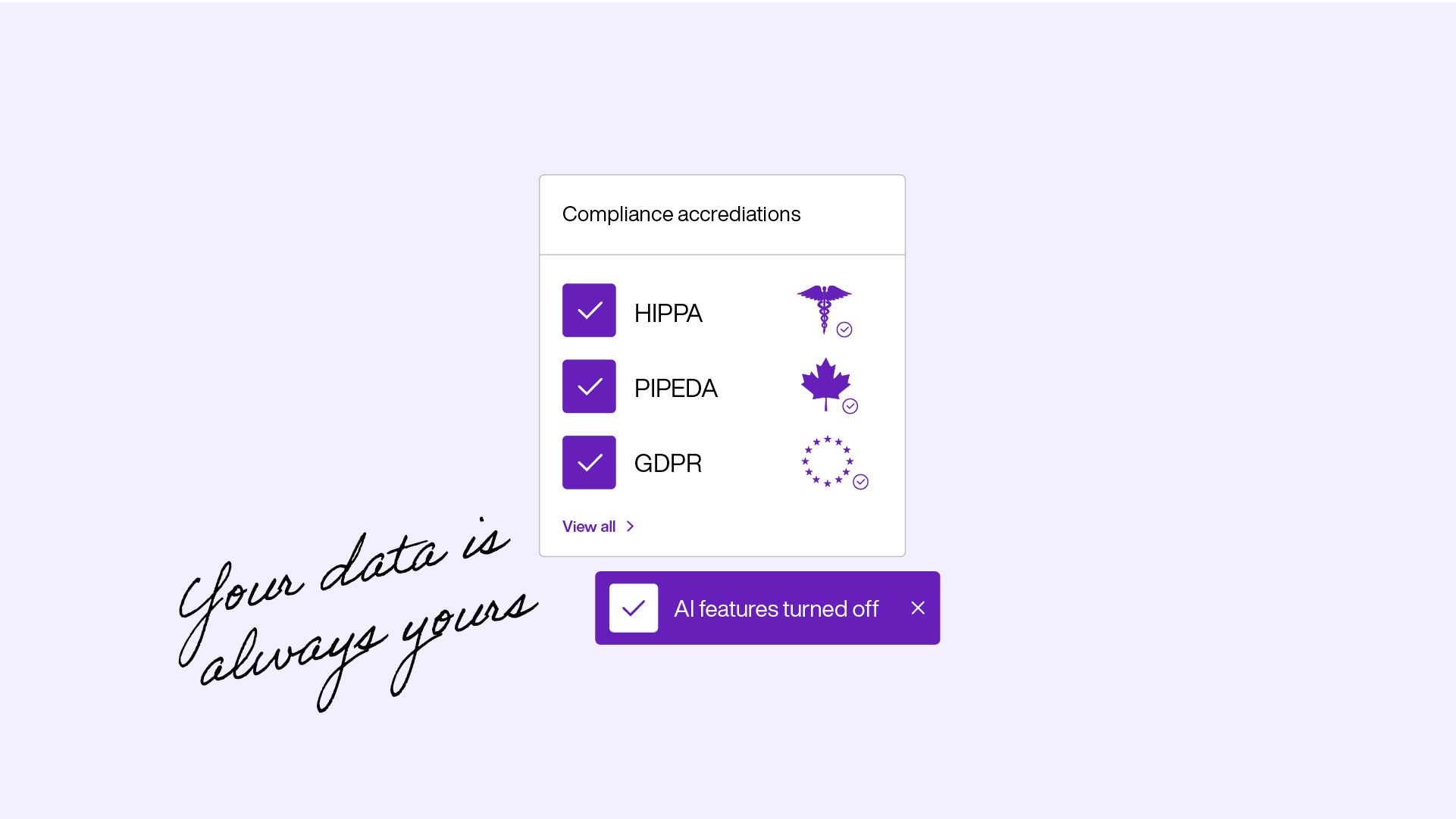
Data privacy
Your data is yours. Full stop.
AI should make your practice better without making your clients' data less safe. You control what AI does in your workspace. It's a tool, not a takeover.
- No client data used for AI model training
- HIPAA, GDPR, and SOC 2 Type II compliant
- Full control. Turn AI features on or off at any time
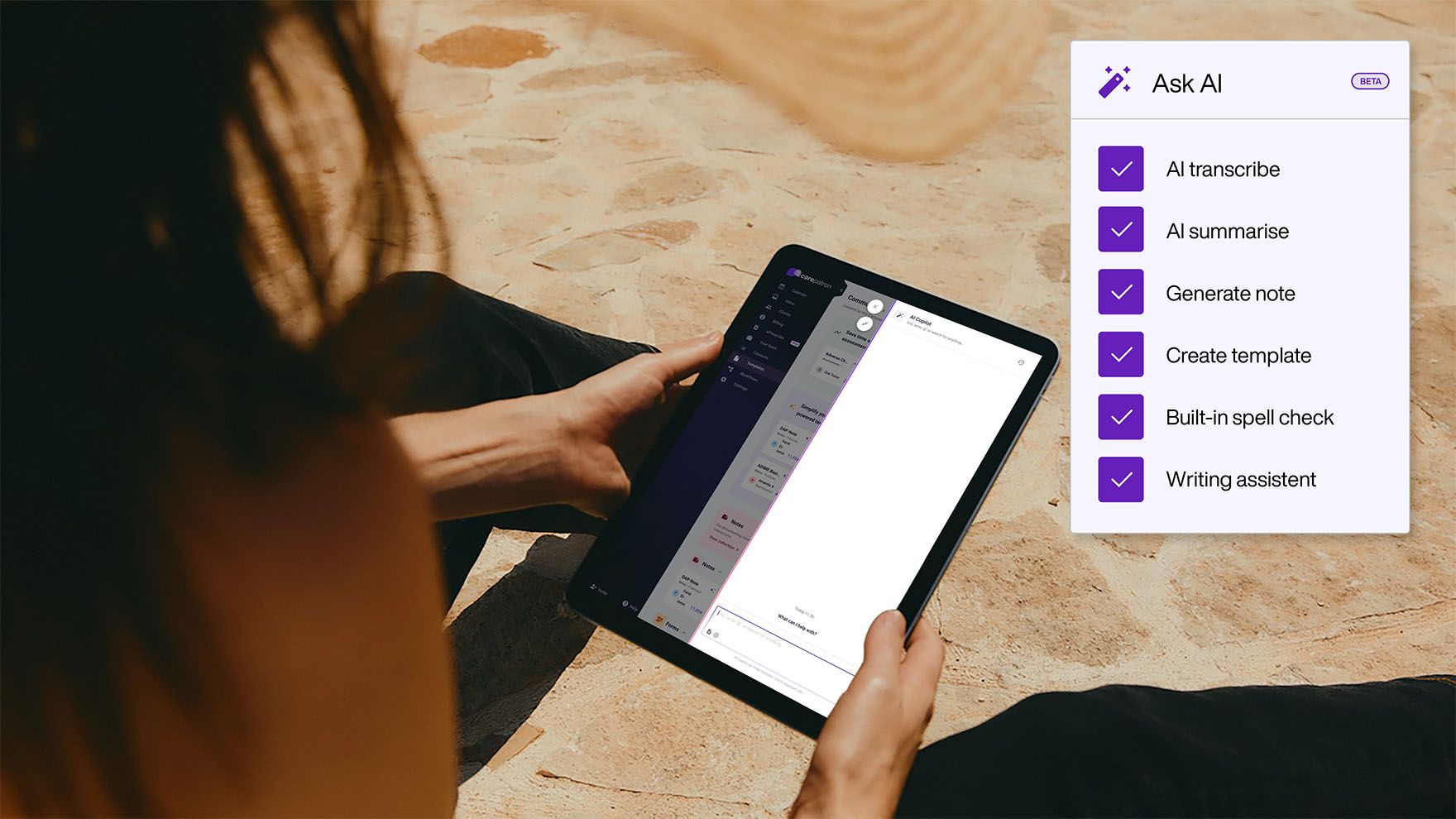
Your voice
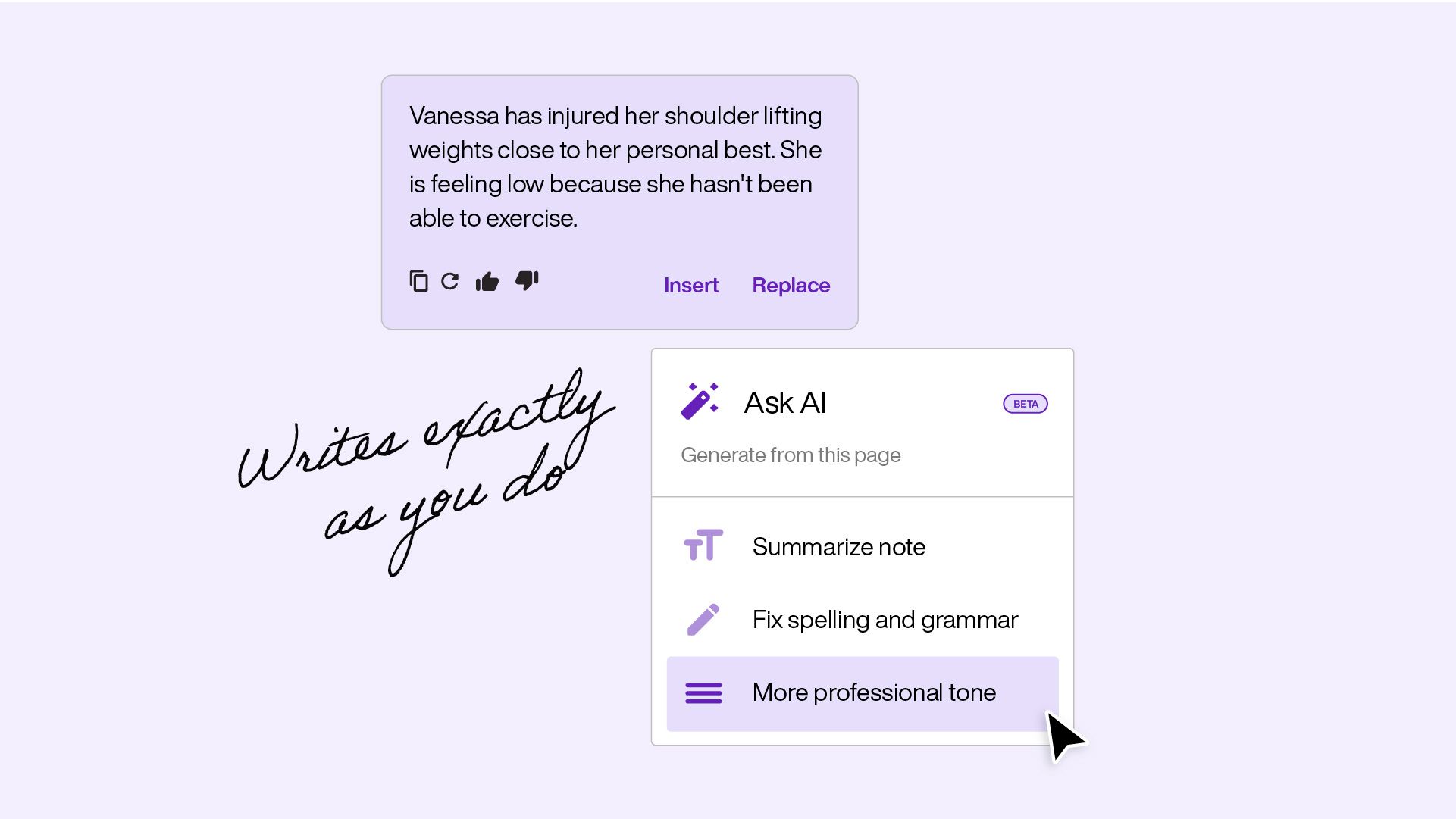
Writes how you write
AI drafts your notes, cleans up your documentation and suggests treatment goals. The writing gets done faster and still sounds like it came from you.
- AI summarize, grammar cleanup, and spelling correction
- Smart prompts that generate goals and content from session data
- Insert, replace, or append AI-generated content to existing notes
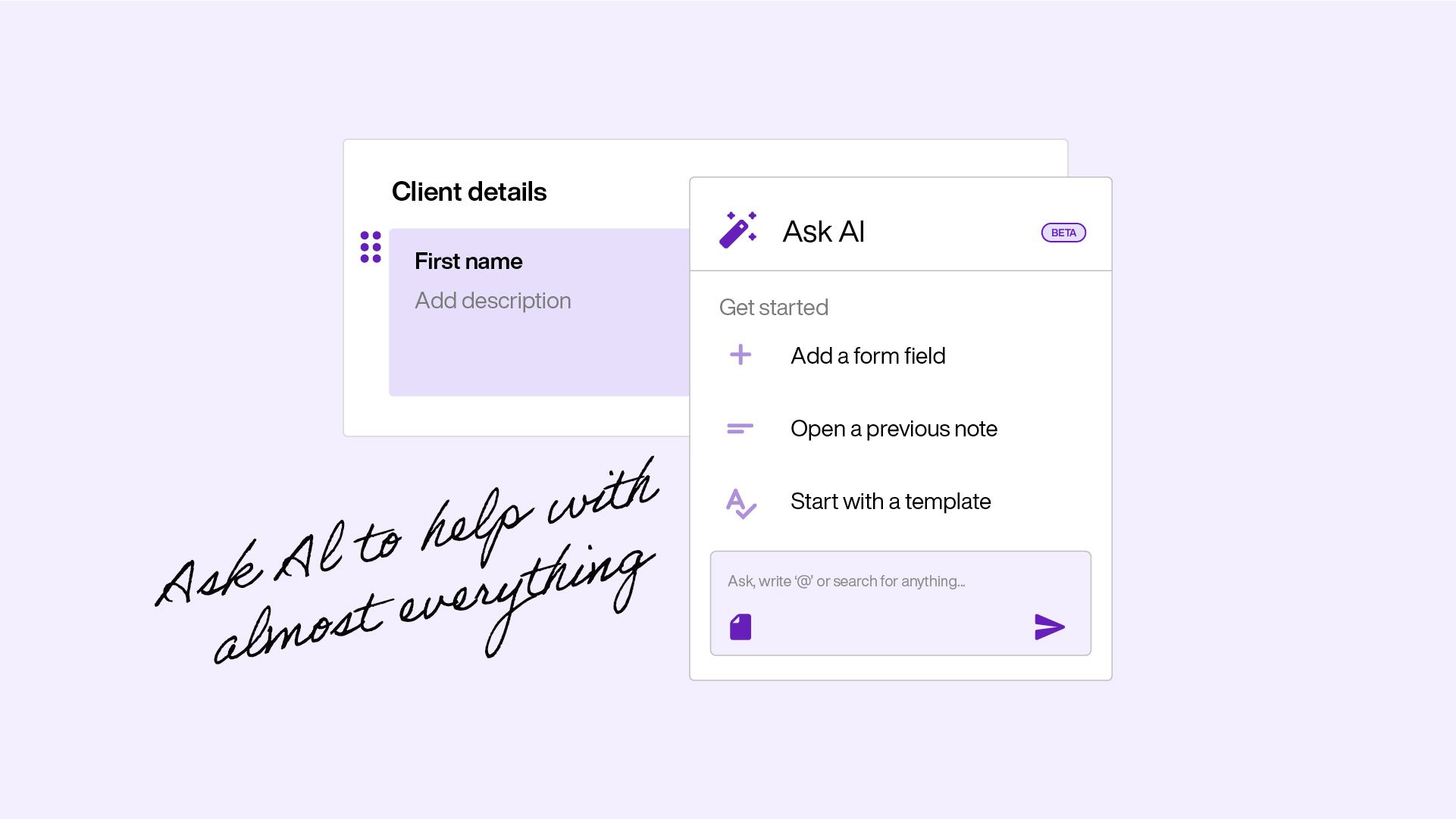
Ask AI
Just ask
Open the AI side panel while you're in a client's note. Ask about their history, past sessions, completed forms or uploaded documents. No switching between tabs or re-reading old notes – the answers are right there beside your work.
- Context-aware answers from the client record, notes, and documents
- Upload PDFs and images for AI to reference
- Smart suggestions that adapt based on whether your note is blank or populated